

2025年1月20日、DeepSeekが開発したDeepSeek-R1が発表されました。オープンソースであり推論モデルが公開されているため個人のPCをはじめとしたローカル環境上で動作させることができます。
今回は色々な意味で世間を騒がせているDeepSeek-R1をRaspberry Pi 5の上で動かして、手のひらサイズのローカルLLMを体験してみたいと思います。
なお、本記事は動画の内容をさらに発展させた内容になっています。動画の方もぜひあわせてご覧ください。
今回作成するもの
ローカルLLMを触るのは初めてなので、とりあえずシンプルにLLMと対話するまでを目標とします。
要件
今回達成すべき要件を以下のように定義しました。
- Raspberry Pi 5(8GBモデル)上で動作する。
- DeepSeek-R1と日本語で対話できるUI(最低限CUIで、できればGUIで)。
- Windows環境で開発して、簡単に移植できる。
- デスクトップPCで動作する場合はGPUを利用できる。
これに合わせた構成を考えていきます。
構成
以上の要件より、構成を以下のように考えました。
- 推論モデルは、DeepSeekの日本語ファインチューニング済みモデルを利用する
- 8GBのRAMで実行できる程度に軽量化された蒸留済みモデルを利用する
- Ollamaを使って推論を実行する
- Linux上で動作する
- 開発はWindows上で行うため、WSL2を利用する
- GUIはOpen-WebUIを利用する
- OllamaやOpen-WebUIのDockerイメージがすでに用意されていることから、Dockerコンテナ構築を視野にいれる
基本的な構成としては、軽量化したモデルとOllamaを用いてLinuxのCLI上で会話することをミニマムサクセスとします。
また、OllamaやOpen-WebUIのDockerイメージがすでに用意されていることからも、Docker移植とGUI実装をフルサクセス、GPUによる推論をエクストラサクセスとします。
セットアップ手順
Linux上で直接環境を構築する場合
まずは推論を実行するアプリケーション「Ollama」をインストールするために、Ollamaの公式HP上に記載されているインストールスクリプトを実行してください。
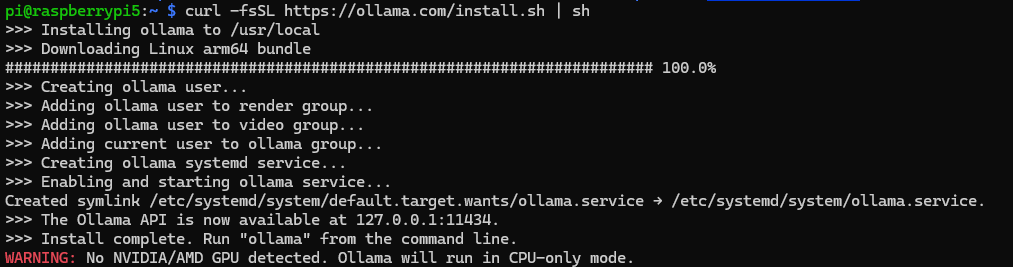
なお、Raspberry PiやオンボードグラフィックスのPC上で実行した場合、GPUが使用できずCPU-only modeでの動作となる警告が表示されます。
Docker上で動作させる場合
今回の企画ではRaspberry Pi 5の上でローカルLLMを動作させることを目的としていますが、Windows PCで開発したり他のLinux環境にも容易に移植ができるように、Dockerを利用して環境のセットアップをしています。「そもそもDockerとは何か」という点については割愛します。
作業マシンがWindowsの場合は DockerDocs から DockerDesktop のインストーラを取得します。また、同時にWindows Subsystem for Linux(WSL2)のセットアップも行ってください。
Linuxのマシンを使用している場合は下記のようにGPG鍵とaptリポジトリを追加し、apt installでDockerをインストールします。
$ curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
$ echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
$ sudo apt update
$ sudo apt install docker-ce containerd.io docker-buildx-plugin docker-ce-cli docker-ce-rootless-extras docker-compose-pluginユーザグループの設定
$ sudo usermod -aG docker $USER
$ newgrp docker動作確認
$ docker --version
Docker version 27.5.1, build 9f9e405
$ docker run --rm hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
c9c5fd25a1bd: Pull complete
Digest: sha256:d715f14f9eca81473d9112df50457893aa4d099adeb4729f679006bf5ea12407
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
...なお、今回のDockerのセットアップにあたっては以下の記事を参考にしました。

推論モデルの準備
DeepSeek-R1のオリジナルの推論モデルは671Bのパラメータサイズがあります。これは671*10^9(6710億)個のパラメータを持つことを意味します。

これを動作させるためには1.3TB程度のVRAMが必要になり、これだけの計算資源を用意することは現実的ではありません。
また、今回はRaspberry Pi 5のRAM8GBモデルの上で動作させることを目的としてるため、推論モデルの容量と推論時の計算量を削る必要があります。
これには主に2つの手法があります。
蒸留(Distillation)と量子化(Quantization)です。
蒸留とは、元の巨大な教師モデルから、より小さい生徒モデルへパラメータ数を減らしながら知識を移植することです。
Qwen2.5やLlamaなどのLLMを生徒モデルとして作成されたDeepSeek-R1の蒸留済みモデルは公式に公開されており、70Bから1.5Bまでの複数の選択肢があります。
また量子化とは、重み付けの変数の精度を32bitFloatから、bit数を減らして精度を下げ、計算量を削減することです。今回は4bitのQ4_K_M型を採用します。
使用するモデルの選定
DeepSeek-R1とその蒸留モデルはそのままでも日本語も解釈してくれますが、日本語によるファインチューニングを施したモデルだとさらに日本語が自然になるかと思います。
HuggingFaceでは、いくつかの日本語ファインチューニング済みモデルがMITライセンスにもとづき公開されています。
例えば、サイバーエージェントが作ったモデルなどがあります。
【モデル公開のお知らせ】
— サイバーエージェント 広報&IR (@CyberAgent_PR) January 27, 2025
DeepSeek-R1-Distill-Qwen-14B/32Bをベースに日本語データで追加学習を行ったLLMを公開いたしました。今後もモデル公開や産学連携を通じて国内の自然言語処理技術の発展に貢献してまいります。 https://t.co/Oi0l2ITzhh

今回はRaspberry Pi 5で動作させるにあたって、LightBlue社製の7Bモデルの日本語ファインチューニング済みモデルを選定しました。

Raspberry Pi 5の16GBモデルや、大きなメモリを積んだPCでは、これよりも大きなモデルも動作させることができるでしょう。
llama.cppを使ったGGUF形式への変換
これまでに紹介したモデルはsafetensorsという形式で公開されています。
この形式はデータサイズが大きく不便なので、端末で扱うためには、モデルデータを汎用的で量子化したモデルにも対応した形式であるGGUF形式に変換する必要があります。
変換が面倒だという方は、この項目をスキップして既製のGGUF変換済みモデルを利用してください。HuggingFaceでは14BモデルのGGUF変換済みモデルはありましたが、7Bモデルは見つけられませんでした。
7Bモデルの量子化済みモデルはこちら
14BモデルではRaspberry Pi 5の8GBモデルではメモリが足りないため動作しません。
GGUF形式への変換のために、llama.cppというツールを利用します。

これは本来LLMによる推論を実行して対話をするためのUIを提供するツールですが、今回はGGUF形式への変換のみに利用します。
ここからはLinux環境での作業が必要になります。CPUパワーなどの都合からWSL2での作業がおすすめですが、モデルを実際に動作させる予定の環境でも作業自体は可能だとは思います。
私はWSL2のUbuntuで作業を行いました。
上記リンクよりllama.cppのリポジトリを適当な場所にcloneし、CMakeを実行してビルドしてください。
次に、使用するモデルのHuggingFaceリポジトリをcloneしてください。Githubと同様に、Gitコマンドで操作できます。
llama.cppに同梱されているconvert_hf_to_gguf.pyでGGUF形式への変換と、ビルドしてできた実行ファイルllama-quantizeを利用した量子化を、以下のように行います。
$ git clone https://huggingface.co/lightblue/DeepSeek-R1-Distill-Qwen-7B-Japanese
$ python convert_hf_to_gguf.py --outfile DeepSeek-R1-Distill-Qwen-7B-Japanese-bf16.gguf --outtype bf16 ./DeepSeek-R1-Distill-Qwen-7B-Japanese/
$ ./build/bin/llama-quantize DeepSeek-R1-Distill-Qwen-7B-Japanese-bf16.gguf DeepSeek-R1-Distill-Qwen-7B-Japanese-Q4_K_M.gguf Q4_K_Mこの例では、16bitのgguf形式に変換した後に4bitのQ4_K_M型で量子化しています。
モデル名やディレクトリの配置などは、ご自身の環境に合わせて適宜読み替えてください。
上記の例の場合、”DeepSeek-R1-Distill-Qwen-7B-Japanese-Q4_K_M.gguf”というファイルが出力されます。
変換は以下の記事を参考にしました。

Gitリポジトリの準備
以下のリポジトリを、実行環境の適当な場所にcloneしておきます。モデルのセットアップやDockerコンテナの立ち上げに必要なファイルが含まれています。
cloneしたリポジトリのroot直下に”models”というディレクトリを作成し、そこに先ほど作成して量子化したモデルデータを配置します。
別のPCでモデルデータを作成した場合、scpコマンドなどを利用して転送するとよいでしょう。
Ollamaへのモデルの登録(Linux上で直接実行する場合)
Dockerを使う場合は、docker build時に自動で実行されるため不要ですので読み飛ばしてください。
先ほどcloneしたリポジトリ内のModelfileを編集します。
冒頭のFROMから始まる行を編集し、modelsディレクトリ内のモデルファイルの場所を指すようにします。
FROM ./models/DeepSeek-R1-Distill-Qwen-7B-Japanese-Q4_K.ggufModelfileの編集が完了したら、以下のコマンドを実行してOllamaにモデルを登録します。登録名はわかりやすいように自由に決めてください。
モデルのファイル名そのままが一番わかりやすいかと思います。
$ ollama create {登録名} -f ./ModelfileDockerコンテナの準備(Dockerを使用する場合)
使用するモデルのファイル名に合わせて、Dockerfile内に記述されているollamaで作成されるモデル名と、ModelfileのFROM以降のパスを修正します。
RUN ollama serve &\
sleep 5 &&\
ollama create DeepSeek-R1-Distill-Qwen-7B-Japanese-Q4_K_M -f /root/.ollama/models/ModelfileFROM /root/.ollama/models/DeepSeek-R1-Distill-Qwen-7B-Japanese-Q4_K_M.gguf
TEMPLATE """{{- if .Suffix }}<|fim▁begin|>{{ .Prompt }}<|fim▁hole|>{{ .Suffix }}<|fim▁end|>
...元のollamaのDockerイメージに、仕様するモデルのggufファイルなどを組み込んだイメージをollama-customという名前で作成します
$ docker build ./ -t ollama-customGPUの準備(NVIDIA)
NVIDIA公式のドキュメントに従ってNVIDIA Container Toolkitをインストールします
このコマンドをLinux実機、もしくはWSL2上で実行します。
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sudo apt-get update
$ sudo apt-get install -y nvidia-container-toolkit本記事では、用意できた機材の都合上、NVIDIAのセットアップについて紹介します。
実行手順
CLI上で直接実行する場合
CLI上で直接実行し、LLMと会話することができます。
--verboseオプションを付けると、LLMの応答終了後にプロンプト評価速度や生成速度などの評価値を表示することができます。
$ ollama run {モデル名} --verboseDockerコンテナの実行
webUIのコンテナと一緒に実行する場合は、docker composeを使います。
推論にCPUを使う場合と、GPUを使う場合で使用するdocker-compose.ymlファイルが異なります。ご使用の環境に合わせてください。
#CPUを使う場合。Raspberry PiではCPUしか使えない。
$ cd Deepseek-R1-CPU
$ docker compose up -dDockerコマンドの使用方法についての説明はここでは割愛します。公式のドキュメントをご確認ください。
Dockerコンテナの中にdocker execコマンドで入って、CLIと同様に操作してCLI上で会話することもできます。
GPUを使う場合(NVIDIA)
GPUの有効無効は、docker composeした際のymlファイルによって変わります
GPU版のdocker-compose.ymlファイルには、NVIDIAのGPUを使用するため以下のような記述があります。
ollama:
image: ollama-custom
container_name: ollama-gpu
runtime: nvidia
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
volumes:
- ollama:/root/.ollama
ports:
- "11434:11434"
networks:
- open-webui-netruntimeとしてnvidiaを指定しています。
実行
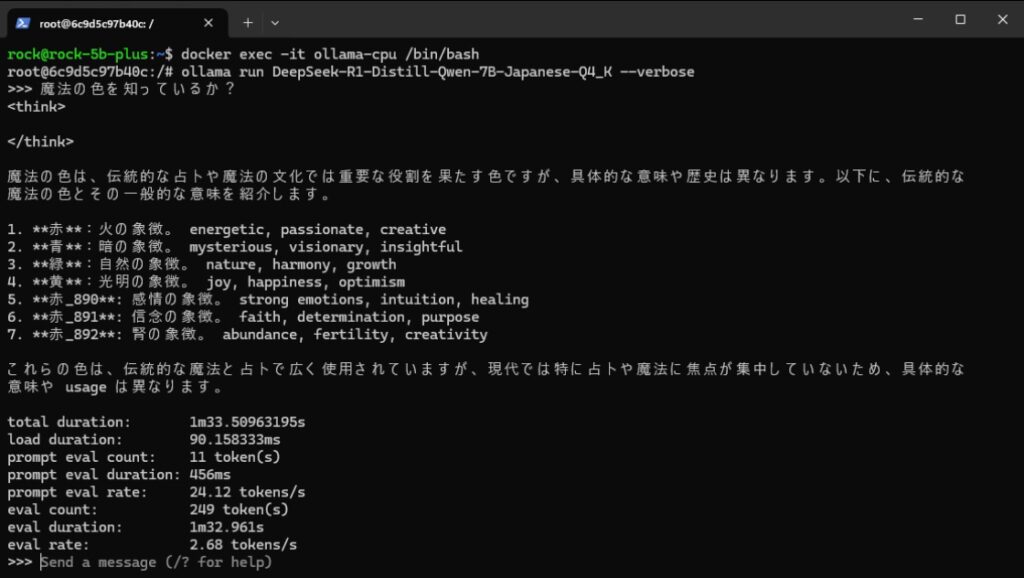
Ollamaが実行されると、CLI上でLLMと会話することができます。
これまでの文脈をクリアしたい場合は/clear、対話を終了したい場合は/byeなどのコマンドが使えます。
Ollama単体でも使用できますが、webUIコンテナが一緒に動いていれば、webブラウザから操作することができます。
webブラウザからRaspberry Pi 5のホストのポート3000宛に接続してみましょう。ChatGPTなどで見慣れたUIが表示されます。
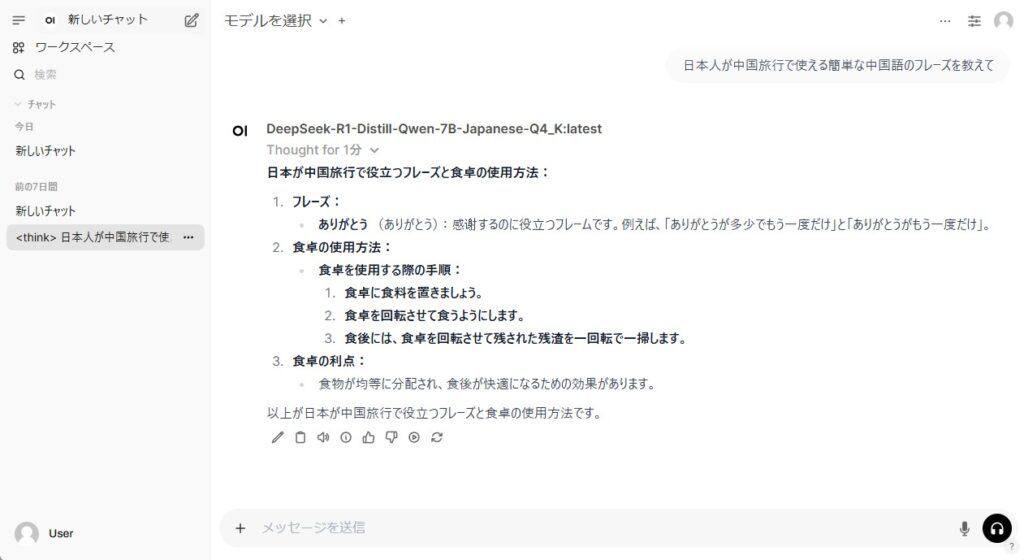
会話しながら、GUI上からモデルの切り替えやtemperature、repeat_penaltyなどの文章の生成にかかわるパラメータを変更することもできます。
注意点など
ストレージ容量について
セットアップ時にscpコマンドで推論モデルをRaspberry Piに転送しようとしたところ、毎度同じパーセンテージで転送が止まってしまう問題につまづき、半日の時間を浪費しました。
原因は単純なことで、ストレージとして使っていた16GBしかないMicroSDカードの容量不足でした。
自分が思っている以上に推論モデルの容量は大きく、MicroSDカードの容量は少ないです。
動作がおかしいと思ったら一旦落ち着いて、次のコマンドでストレージの空き領域を確認してみましょう。
$ df -h容量や読み書き速度の点からも、NVMeハットを取り付けてSSDからブートさせるのが理想です。
RAM容量について
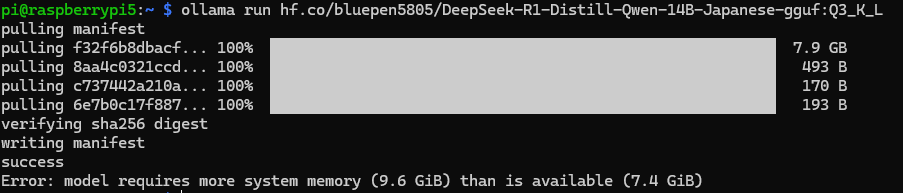
RAM容量の小さいSBCやPCでは、実行可能なモデルのサイズの制約に引っかかる場合があります。
例えば、Raspberry Pi 5で14Bモデルを実行しようとすると、エラーが出て起動できません。
冷却
推論実行時に、かなりの頻度で熱暴走して電源が落ちてしまいます。
これはRaspberry Pi 5純正のファン付きヒートシンクを取り付けていても時折発生しました。
そのため今回の実験は、サーキュレータの上にRaspberry Pi 5本体を裏返しに置いて冷却しながら行いました。

推論速度の比較
CPUとGPUの比較
CPUを使って推論を実行した場合と、GPUを使った場合の生成速度を比較しました。
それぞれに同じプロンプトを数パターン与えて、生成速度を計測して平均を出しています。
使用したPCは、Ryzen 7 7700XとRTX3060tiを搭載したデスクトップPC、使用したモデルはDeepSeek-R1-Distill-Qwen-14B-Japanese-ggufです。
| 平均生成速度[tokens/s] | |
|---|---|
| CPU | 3.59 |
| GPU | 6.86 |
CPUに対して、GPUではおよそ2倍程度の速度が出ました。
PCとRaspberryPiの比較
条件を揃えるために、PCでも7Bモデルを実行し、同じプロンプトを与えてRaspberry Pi 5と動作を比較しました。
PCではGPUを使用しています。
| 平均生成速度[tokens/s] | |
|---|---|
| Raspberry Pi 5 | 2.31 |
| PC | 81.52 |
ソースコード生成実験
Raspberry Pi 5上で動作する7Bモデルと、PC上で動作する14Bモデルに、それぞれ同じプロンプトを与えてソースコードを生成させる実験を行いました。
「円周率の近似値を計算するプログラムをPythonで作ってください。」というプロンプトを与え、生成されたソースコードを実際に動かしてみる実験を行います。
模範解答としては、乱数を使って座標が単位円内に収まるかを判定するモンテカルロ法か、arctanを計算するマチンの公式を想定しています。
7Bモデル
何度か生成を行ったところ、355/113など分数を使った近似や、グレゴリー級数を使った方法が生成されました。
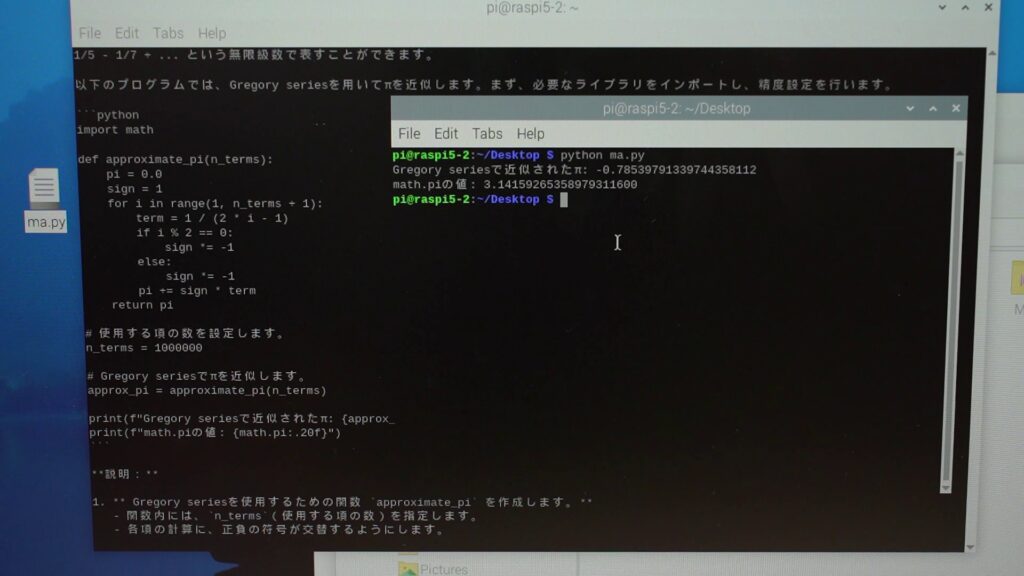
生成されたソースコードを実行してみましたが、計算がそもそも間違っていたり、Pythonで重要なインデントが崩れていたりするなど、正常に動作しないものが多いようです。
また、ハルシネーションを起こして存在しない方式を捏造して紹介してきたこともありました。
14Bモデル
こちらも何度か生成を行い、モンテカルロ法のコードを得ることができました。
実際に実行してみても、正常に動作するコードが多く生成されました。
これは実際に生成されたコードの一例です。これをそのままコピペして実行することで、高精度な円周率の近似値を得ることができました。
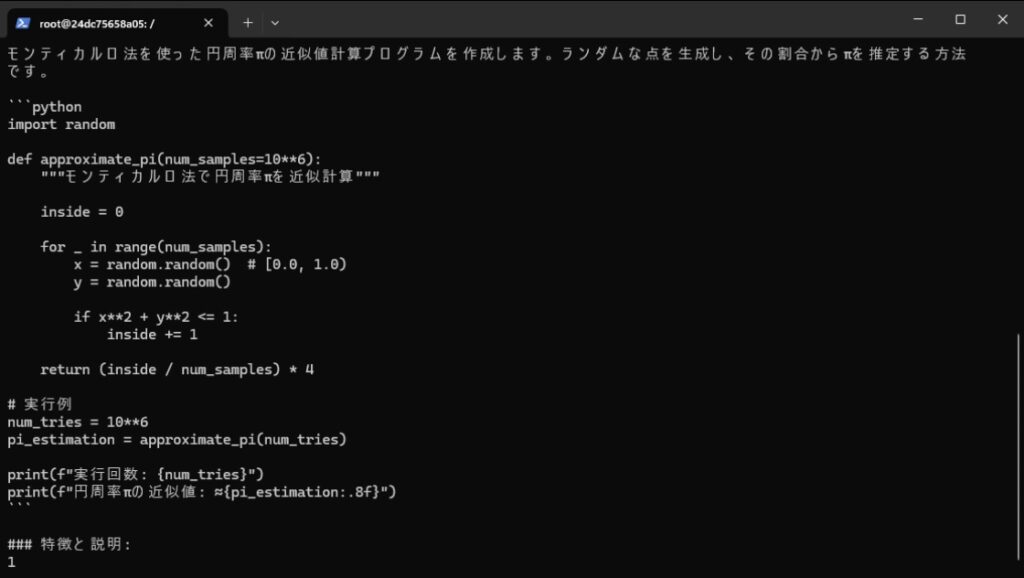
しかし14Bモデルにおいても、存在しない方式名とソースコードの捏造は時折発生していました。
Raspberry Pi 5以外のシングルボードコンピュータでの動作
Rock5B
Docker環境さえ構築できれば、Raspberry Pi以外のSBCで動作させることも簡単にできます。
Raspberry Pi 5同様、RAM8GBのRock5Bでの動作も確認してみました。

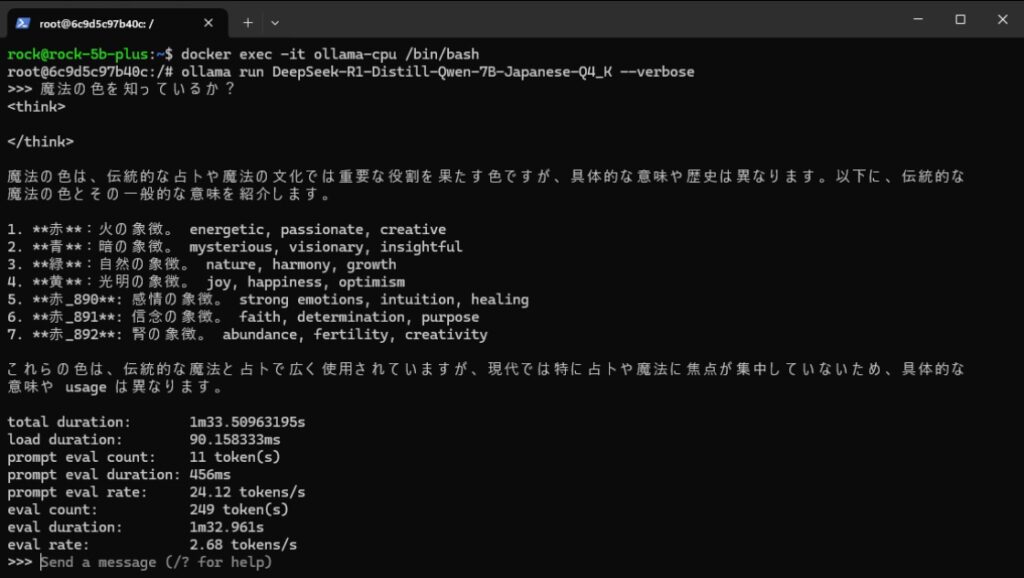
Rock5Bでも7Bモデルを動作せることができました。熱暴走しない分、Raspberry Piより優秀かもしれません。
まとめ
ここまでDeepSeek-R1を動かしてみて、ローカルLLM技術の一端に触れてみることができました。
さすがにRaspberry Piのようなリソースが限られた環境で動く程度のLLMでは、ChatGPTのような流暢な会話は難しいような印象を受けました。
しかし、当初の目標であるLLMとの会話と、Docker移植とGUI実装は実現することができたため、フルサクセスは達成することができたと言って良いでしょう。
一方でGPUを使った推論については、今回はPCに搭載したNVIDIAのグラフィックボードを使うにとどまりました。
Raspberry PiのPCIeレーンにGPUを接続して推論を行うことで処理を高速化するなど、まだまだ改良の余地はあるように感じたので、それは次回までの課題とします。
LLMの用途は人間との会話だけではありません。ラバーダックデバッギングを含むコーディング支援やテキストの翻訳など、特定の用途に特化させた使い方であれば、十分に役に立つのではないかという可能性も感じました。
そのためには、目的に合わせたデータセットの作成とラーニングが必要になります。こういったものが個人でも作れる時代がもう来ていることを思うと、感慨深いものがあります。
本記事を呼んでローカルLLMにご興味を持たれた方は、ぜひご自身で動かして試してみてください。
今回紹介したソフトウェアはすべて無料で使うことができます。
(一部例外あり。Docker Desktopは個人利用と小規模ビジネスのみ無料。)
本記事の内容の元になった動画も改めてご紹介します。ぜひご確認ください。





コメント
コメント一覧 (1件)
いつも気になる技術に関する動画を楽しみに拝見させていただいております。
ラズパイでLLMを動かせると知ってこのサイトを参考にさせいただき、ラズパイ5でLLMを動かすことができました。
既知の情報かもしれませんが、環境構築の際に詰まった箇所をコメントさせていただきます。
llama.cppを使ったGGUF形式への変換の項目でconvert_hf_to_gguf.pyを使ったGGUF形式への変換時にエラーが出て進む事が出来ませんでした。
解決方法はgit lfs cloneを使ってDeepSeek-R1-Distill-Qwen-7B-Japaneseをクローンすることで解決しました。
解決方法の参考サイト→https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct/discussions/123