

今回は、大量の演算を並列化して高速化する技術について紹介します。

数値流体解析(CFD)で広く使われているオープンソースソフトウェアOpenFOAMは、計算規模が大きくなればなるほど計算時間も長くなりがちです。
空間内を分割するメッシュ数を増やしたり、時間刻みを細かくしたりすると、単一マシン・単一プロセスでは現実的な時間で計算を終えるのが難しくなります。
そこで活躍するのがMPI(Message Passing Interface)を用いた並列計算です。
OpenFOAMにはOpenMPIがバンドルされており、OpenFOAMの並列演算はそれを使った方法が一般的です。
しかし本記事では、Minisforumのミニワークステーション、MS-02 Ultraに搭載されている高速ネットワーク、強力なCPU、巨大なメモリを最大限に活用するため、OpenFOAMをソースコードからビルドし、IntelMPIと連携させる方法を解説します。
本記事で解説する主な内容は以下の通りです。
- IntelMPI と RDMA を使ったOpenFOAM環境の構築
- OpenFOAMのソースからのビルド手順
- MPI を使った OpenFOAM 並列計算の実行方法
- 実行確認やつまずきやすいポイント
といった内容を、本記事では実際に手を動かしながら再現できる形で解説していきます。
「OpenFOAMをもっと速く使いたい」「IntelMPIを使って複数台PCでクラスタリングしてみたい」という方は、ぜひ参考にしてみてください。
なお、本記事の内容は動画でも公開しています。こちらも併せてご覧ください。
使用機材
演算には、ミニワークステーションMinisforum MS-02 Ultraを使用します。

- Minisforum MS-02 Ultra(*3台)
- Ubuntu
- Intel Core Ultra9 285HX
- 192GB RAM
- 25GbE SFP+ ポート
- Ubiquiti USW-Aggregation スイッチ

MS-02 UltraにはSSDを追加してUbuntuをインストールしてあります。
3台中1台をマスタとし、それ以外をスレーブとしています。今回は、それぞれホスト名をCASPAR, BALTHASAR, MELCHIORとし、CASPARとマスタとして運用しています。
MS-02 Ultraには複数のネットワークインターフェイスが搭載されていますが、今回はSFP+ポートを使用します。

SFPポートを使用するのには速度のほかにもう一つ理由があり、イーサネットコントローラ Intel E810 がRDMA(Remote Direct Memory Access)に対応しているためです。

これにIntelMPIを組み合わせることでさらに高速な並列演算が可能になります。
なお、Ubiquiti USW-Aggregationの速度が10Gbpsのため、実効速度は最大10Gbpsになります。
また、SFPを使うため今回は問題ありませんが、Ubuntu標準のドライバでは、MS-02 Ultraに搭載されている10GbE RJ45ポートが使用できません。これはUbuntuがイーサネットコントローラ Realtek R8127のドライバを内蔵していないためです。
Realtek R8127用のドライバのビルドには以下の記事が参考になりますので、必要な方はご確認ください。

また、スレーブノードはマスタノードからSSHの公開鍵認証で接続できるようになっている必要があります。SSHの設定については後述します。
ここで紹介したハードウェア構成と同じでなくても、RDMAを利用可能なネットワークインターフェイスが搭載されていれば、IntelMPIを使った方式は同じ考え方で実現可能かと思います。
SSHの設定(マスタノード)
マスタからスレーブへ、SSHをパスワード入力なしで接続できるようにします。
鍵生成(なければ)
ssh-keygen -t ed25519公開鍵コピー。今回の例では各ノードで異なるユーザ名を設定しています。
ssh-copy-id ichiken2@balthasar
ssh-copy-id ichiken3@melchiorSSHのconfigファイル~/.ssh/configの設定。 各ノードでユーザ名が異なる場合は、ホスト名だけで接続できるようにユーザ名を設定しておきます。
Host balthasar
HostName 192.168.1.XXX
User ichiken2
Host melchior
HostName 192.168.1.XXX
User ichiken3
Host caspar
HostName localhost
User ichiken1
確認
ssh balthasar hostname
ssh melchior hostnameOpenFOAMとIntelMPIの環境構築
本章では、OpenFOAMをソースコードからビルドし、IntelMPIとリンクさせることで、RDMAによる高速通信を可能にする環境を構築します。
この手順は、マスタ・スレーブすべてのノードで実行する必要があります。
IntelMPI (oneAPI) のインストール
はじめに、Intel oneAPIの中からIntel MPIライブラリをインストールします。
# 依存パッケージをインストール
sudo apt update
sudo apt -y install wget gpg ca-certificates
# Intel oneAPI のリポジトリキーを追加
wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB \
| gpg --dearmor | sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg >/dev/null
# リポジトリを追加
echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" \
| sudo tee /etc/apt/sources.list.d/oneAPI.list
# パッケージリストを更新し、Intel MPIをインストール
sudo apt update
sudo apt -y install intel-oneapi-mpi intel-oneapi-mpi-develインストール後、環境設定スクリプトを読み込んで動作を確認します。
source /opt/intel/oneapi/setvars.sh
mpirun --versionIntel(R) MPI Library という表示が確認できれば成功です。
RDMAスタックのインストール
次に、RDMA通信に必要となるパッケージをインストールします。
sudo apt -y install rdma-core ibverbs-providers infiniband-diags perftestインストール後、RDMA対応デバイスが認識されているか確認します。
ibv_devices
rdma linkLINK_UP のポートが表示されれば、物理的な接続は正常です。
OpenFOAMのソースコード準備
IntelMPIで利用するOpenFOAMは、APTでインストールしたものではなく、ソースコードからビルドしたものを使用します。
まず、ビルドに必要なパッケージをインストールします。
sudo apt -y install build-essential flex bison cmake git zlib1g-dev libfftw3-dev libscotch-dev libptscotch-dev libopenblas-dev libreadline-dev libncurses-dev libxt-dev libx11-dev次に、OpenFOAM v2512のソースコードをダウンロードし、展開します。
# ここでは例として ~/src/openfoam に展開
mkdir -p ~/src/openfoam
cd ~/src/openfoam
wget https://dl.openfoam.com/source/v2512/OpenFOAM-v2512.tgz
wget https://dl.openfoam.com/source/v2512/ThirdParty-v2512.tar.gz
tar -xJf OpenFOAM-v2512.tgz
tar -xJf ThirdParty-v2512.tar.gzこれ以降の手順では、以下の環境変数を読み込んで行う必要があります。
source /opt/intel/oneapi/setvars.sh
source ~/src/openfoam/OpenFOAM-v2512/etc/bashrcもし、動画内で解説したようにIntelMPIとOpenMPIの共存環境を作る場合は、ターミナルを開く都度環境変数の読み込みを実行する必要があります。
IntelMPIのみを利用する場合は、bashrcに書き込むことでターミナルを開くたびに環境変数が自動で設定されるようにするとよいでしょう。
OpenFOAMのビルド (IntelMPI用)
展開したソースコードをIntelMPIでビルドするよう設定します。
prefs.sh という設定ファイルを作成し、使用するMPIライブラリとしてIntelMPIを指定します。
cd ~/src/openfoam/OpenFOAM-v2512
cat > etc/prefs.sh <<'EOF'
export WM_MPLIB=INTELMPI
export MPI_ROOT=/opt/intel/oneapi/mpi/latest
EOF設定を反映させるために、環境変数を読み込みます。
# oneAPIとOpenFOAMの環境を読み込む
source /opt/intel/oneapi/setvars.sh
source ~/src/openfoam/OpenFOAM-v2512/etc/bashrc
# 設定が反映されているか確認
echo $WM_MPLIB
# INTELMPI と表示されるはず準備が整ったら、ビルドを実行します。CPUのコア数に応じて -j オプションで並列数を指定するとビルドが高速化します。
cd ~/src/openfoam/OpenFOAM-v2512
./Allwmake -jビルド結果の確認とノードへの配置
ビルドが完了したら、OpenFOAMのソルバーがIntelMPIライブラリにリンクされているか確認します。
# 環境変数を再度読み込む
source /opt/intel/oneapi/setvars.sh
source ~/src/openfoam/OpenFOAM-v2512/etc/bashrc
# lddでライブラリのリンクを確認
ldd $(which interFoam) | grep "libmpi.so"出力に /opt/intel/oneapi/mpi/ へのパスが含まれていれば、正しくリンクされています。
最後に、マスタノードにあるOpenFOAMのソースコードを、他のスレーブノードに rsync などでコピーします。
このとき、各ノードですべて同じディレクトリである必要があります。
これは環境変数の参照などで必要になります。
# balthasar, melchiorノードにコピーする例
rsync -a --delete ~/src/openfoam/OpenFOAM-v2512/ balthasar:/home/ichiken1/src/openfoam/OpenFOAM-v2512/
rsync -a --delete ~/src/openfoam/OpenFOAM-v2512/ melchior:/home/ichiken1/src/openfoam/OpenFOAM-v2512/以上で、IntelMPI版OpenFOAMの環境構築は完了です。 これ以降の並列計算の実行方法はOpenMPI版と同様ですが、mpirunコマンドなどはIntelMPI版が使用されることになります。
mpiコマンド動作確認
MPIコマンドが正しく動作するかを確認します。
mpirunコマンドのパス確認
which コマンドで mpirun のパスを確認します。
source /opt/intel/oneapi/setvars.sh # IntelMPIの環境変数を読み込む
which mpirun
#期待される応答
#/opt/intel/oneapi/mpi/2021.17/bin/mpirun (バージョンは異なる場合があります)単一ノードでのMPI動作確認
mpirun -np 2 hostname を実行し、単一ノード内で2つのプロセスが起動し、ホスト名が出力されることを確認します。
source /opt/intel/oneapi/setvars.sh
source ~/src/openfoam/OpenFOAM-v2512/etc/bashrc # IntelMPIでビルドしたOpenFOAMの環境を読み込む
mpirun -np 2 hostname
#期待される応答:
#CASPAR
#CASPAR複数ノードでのMPI動作確認
IntelMPIは、複数ホスト複数スレッドの指定に-machinefileというオプションを使用します。
machinefileとして各ノードのスレッド数を指定するファイルを任意の場所に作成します。ファイルの内容は、使用するスレッド数分のホスト名を記述します。
cat > ~/hosts_intelmpi <<'EOF'
caspar
caspar
# ...
balthasar
balthasar
# ...
melchior
melchior
# ...
EOF今回は、MPIの疎通確認なので、各ノード1スレッドのmachinefileを作成します
caspar
balthasar
melchiormpirun を使用して、複数のノードでプロセスが起動し、それぞれのホスト名が返されることを確認します。
source /opt/intel/oneapi/setvars.sh
source ~/src/openfoam/OpenFOAM-v2512/etc/bashrc # IntelMPIでビルドしたOpenFOAMの環境を読み込む
mpirun -np 3 -machinefile ~/hosts_intelmpi_3threads hostname
#各ノードのホスト名が返ってくる
#CASPAR
#MELCHIOR
#BALTHASAR複数ノードでのOpenFOAM環境動作確認
OpenMPI経由で、他ノードのOpenFOAM環境が正しく読み込まれるかを確認します。
mpirun -np 3 -machinefile ~/hosts_intelmpi_3threads \
bash -lc 'source /usr/lib/openfoam/openfoam2512/etc/bashrc; \
echo $HOSTNAME $WM_PROJECT_VERSION'
#期待される応答:
#CASPAR v2512
#BALTHASAR v2512
#MELCHIOR v2512並列計算の実行
環境構築が完了したら、いよいよIntelMPIを使ってOpenFOAMの並列計算を実行します。
ここでは例として、空間内で流体の塊が決壊する様子をシミュレーションする damBreak チュートリアルケースを用います。以降の作業は、特に断りがない限りマスタノード(CASPAR)で実行します。
実行準備
環境変数の読み込み
並列計算を実行する前に、使用するMPIライブラリとOpenFOAMの環境変数を読み込む必要があります。
ビルドしたIntelMPI版OpenFOAMを使用する場合、以下のコマンドで環境変数を読み込みます。
source /opt/intel/oneapi/setvars.sh
source ~/src/openfoam/OpenFOAM-v2512/etc/bashrc~/.bashrcに設定している場合は不要です。
チュートリアルケースの準備
OpenFOAMのチュートリアルケースをコピーし、実行環境を準備します。ここでは damBreak ケースを例とします。
# このディレクトリで実行される。適宜変更してください。
cd /home/ichiken1/OpenFOAM/run
# damBreakケースをコピー。任意のケースに置き換えてください。
cp -r $FOAM_TUTORIALS/multiphase/interFoam/laminar/damBreak/damBreak damBreak
cd damBreak
# (前回の実行結果が残っている場合のみ)初期化。
# ログファイル、0ディレクトリ、.formファイルまで消える点に注意。
# 必要なければスキップしてください。
./Allclean
# 分割数変更のみであれば、Allcleanは不要。
# processor*ディレクトリの削除のみでよい。
rm -rf processor*
# 0ディレクトリ初期化
cp -r 0.orig/ 0/
# メッシュ作成
blockMesh
# 空間を初期状態で塗り分け (ダムブレイク系なら必要)
setFields
# ParaView用ファイル作成
# .foamファイルを作成する。ファイル名は任意。内容は空でよい。
touch damBreak.foam計算領域の分割と配置
計算領域の分割
並列計算を実行するために、計算領域をサブドメインに分割します。system/decomposeParDict ファイルの numberOfSubdomains パラメータで分割数を指定し、decomposePar コマンドで実行します。
合計72分割(各ノード24スレッド x 3ノード)の例:
# numberOfSubdomains を72に設定
sed -i 's/numberOfSubdomains .*/numberOfSubdomains 72;/' system/decomposeParDict
# 必要であれば古いprocessorディレクトリを削除
rm -rf processor*
# 計算領域を分割
decomposeParスレーブノードへのデータ転送
分割された計算領域のデータ(processor* ディレクトリなど)を、rsync コマンドを使用してスレーブノードに転送します。これにより、各ノードが自身の担当する計算領域のデータにアクセスできるようになります。
# melchiorノードへ転送
rsync -rlDv --delete --no-owner --no-group --no-times /home/ichiken1/OpenFOAM/run/ melchior:/home/ichiken1/OpenFOAM/run/
# balthasarノードへ転送
rsync -rlDv --delete --no-owner --no-group --no-times /home/ichiken1/OpenFOAM/run/ balthasar:/home/ichiken1/OpenFOAM/run/並列計算の実行と結果の統合
machinefileの準備
今回の例では、合計72スレッド(各ノード24スレッド x 3ノード)使用します。そのため各ホスト名を24回ずつ記述します。
cat > ~/hosts_intelmpi <<'EOF'
caspar
caspar
# ... (casparを合計24回記述)
balthasar
balthasar
# ... (balthasarを合計24回記述)
melchior
melchior
# ... (melchiorを合計24回記述)
EOF並列計算の実行
すべての準備が整ったら、mpirun コマンドを使用して並列計算を実行します。
合計72スレッドで interFoam ソルバをMPI分散処理で実行する例です。
mpirun -np 72 -machinefile ~/hosts_intelmpi \
bash -lc 'source /home/ichiken1/src/openfoam/OpenFOAM-v2512/etc/bashrc; interFoam -parallel'
ログ出力について:
- 標準出力とファイルへの同時出力: 計算の進行状況をターミナルに表示しつつ、ログファイルにも保存する場合に利用します。
| tee log.interFoam.cluster72 - 標準出力なしでファイルにのみ出力: ターミナルへの出力を抑え、ログファイルにのみ保存する場合に利用します。
ExecutionTimeは変わりませんが、ClockTimeが多少短縮されることがあります。> log.interFoam.cluster72 2>&1
これらのログ出力コマンドは、上記の mpirun コマンドの末尾に追加して使用します。
計算結果の収集
並列計算が終了したら、各スレーブノードに分散して保存されている計算結果(processor* ディレクトリ内のデータ)を、マスタノードのケースディレクトリに収集します。rsync コマンドを使用すると効率的です。
rsync -ar balthasar:/home/ichiken1/OpenFOAM/run/damBreak/damBreak/processor* /home/ichiken1/OpenFOAM/run/damBreak/damBreak
rsync -ar melchior:/home/ichiken1/OpenFOAM/run/damBreak/damBreak/processor* /home/ichiken1/OpenFOAM/run/damBreak/damBreak計算結果の統合
収集した各プロセッサディレクトリのデータを、reconstructPar コマンドを使用して単一の計算結果として統合します。これにより、ParaViewなどで可視化できるようになります。
reconstructPar結果の確認
計算時間の確認
計算が完了したら、ログファイルから計算時間を確認できます。ExecutionTime は純粋な計算時間、ClockTime は実時間を表します。
grep -E "ExecutionTime|ClockTime" log.interFoam.cluster72 | tail -n 5期待される出力例:
ExecutionTime = ... s ClockTime = ... s
ExecutionTime = 33.05 s ClockTime = 33 sParaViewによる可視化
計算結果はParaViewというソフトウェアを用いて可視化できます。CASPARのGUI環境でParaViewを起動し、以下の手順で結果を表示します。
- ParaViewを起動します。
- [File] -> [Open] を選択し、実行前にケースディレクトリ内に作成した
.foamファイル(例:damBreak.foam)を選択します。 - 表示されるダイアログで、“Skip Zero Time” のチェックを外し、[Apply] ボタンをクリックします。
- 左側の Properties パネルで、可視化したいデータ(例:
alpha.water液体領域など)を選択し、[Apply] をクリックして表示します。
性能比較:OpenMPI vs IntelMPI
本記事で構築したIntelMPI環境の効果を測定するため、標準的なOpenMPI環境とで計算速度を比較しました。
動画内で紹介した事前の実験で、1スレッドあたりが担当するメッシュ数を大きくすると、スレッド数とシミュレーション完了までの時間に逆相関が見られることがわかっています。
つまり、メッシュ数が十分に多ければ、総メッシュ数に対してスレッドが増えるほど実行時間が短くなる傾向があるということです。逆に言えば、メッシュ数が少ない場合、通信のレイテンシなどの影響を受け、ノード数が多いほど処理が遅くなるという減少が確認されていました。
そのため今回の検証では、1スレッドあたりのメッシュ数を十分に増やしたdamBreakケースを用意し、全く同じ条件でMPIライブラリのみをOpenMPIとIntelMPIで切り替えて実行時間の比較を行いました。
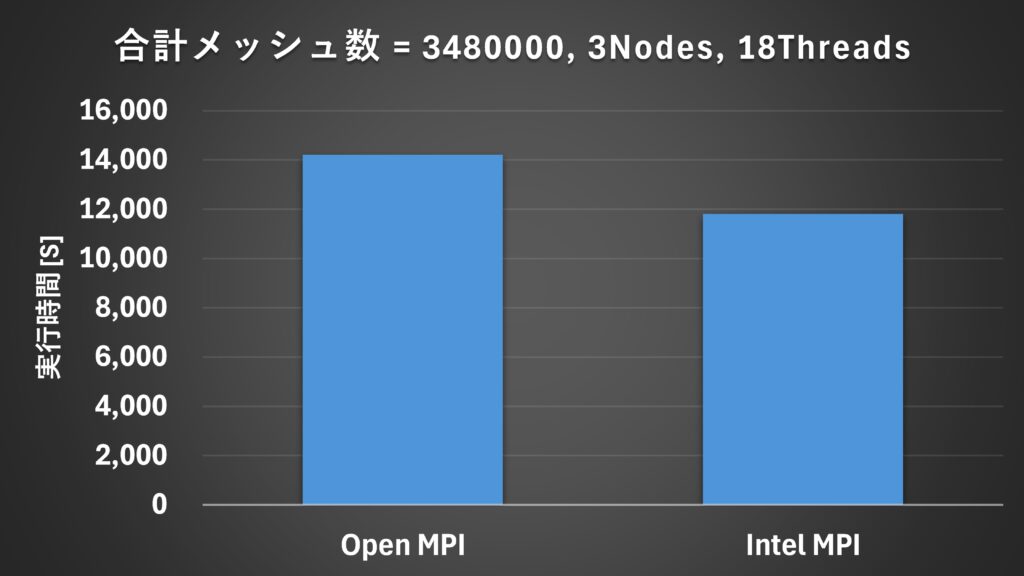
その結果、IntelMPI環境では、OpenMPI環境に比べて計算時間が約17%短縮されました。これは、RDMAによって通信オーバーヘッドが削減されたことによる効果と考えられます。
なお、Intel E810はOpenMPIでのRDMA利用にも対応していますが、そちらは最適化の難易度が高いことから今回は検証を見送りました。今後の課題として、機会があれば挑戦してみたいと思います。
まとめ
今回は、Minisforumのミニワークステーション「MS-02 Ultra」を3台使用し、クラスタ環境でOpenFOAMによる数値流体解析の可能性を探りました。
MS-02 Ultraは、コンパクトな筐体ながら、多数のCPUコアと大容量メモリ、高速ネットワークを兼ね備えたユニークなマシンです。
特定の通信特性と演算能力が求められる並列計算において、その小型さと費用対効果は大きな魅力となるかと思います。
特にOpenFOAMを用いた数値計算の分野では、ある一定のところまではMS-02 Ultraの24コア/24スレッドCPU性能と、RDMA対応の高速ネットワークが非常に有効であることが分かりました。
くわしい解説などはぜひ動画のほうをご覧ください。
本記事で扱ったIntelMPI以外にも、OpenMPIによる並列演算を利用してモンテカルロ法により円周率を計算するスクリプトを実行したり、大容量のメモリを利用して671BサイズのLLMを動作させるなど、並列演算を用いた色々な実験を行っています。
それでは、最後までお付き合いいただきありがとうございました。





コメント