

前回の記事で、Raspberry Pi 5にGPUを外付けして動作させる実験を行いました。Raspberry Pi 5にサードパーティのLinuxカーネルをコンパイルしてインストールし、接続したAMD製のGPUから映像出力することに成功しました。
その記事まだご覧になっていない方は、以下よりご確認ください。

今回は、前回作ったこの外付けGPUを使って、Raspberry Pi 5の上で大規模言語モデルによる推論を動作させるエッジAIシステムを構築してみたいと思います。
本記事の内容は動画でも公開しておりますので、そちらも併せてご覧ください。
ハードウェア構成
使用する機材は前回作ったものから変更はありませんが、改めて紹介しておきます。
Raspberry Pi 5のRAM16GBモデルに、NVMeハットとPCIeライザーを経由してグラフィックボードを接続しています。
グラフィックボードはRadeon RX6600XTという機種を中古で手に入れました。また、GPUが使えるメモリであるVRAMは8GB搭載されています。

ソフトウェア構成
Llama.cpp
以前の動画では、推論を実行するアプリケーションとしてOllamaを使いましたが、今回はLlama.cppを使います。

以前使ったOllamaはLlama.cppのラッパーで、内部的にはやっていることは同じです。
以前、Raspberry Pi上でDeepSeek-R1を動作させた際に、今後の拡張性と移植性を考慮してDockerでOllamaを動かせるように開発していましたが、残念ながら今回の企画には流用はできませんでした。
それはGPUを制御するために利用するAPIの都合によるものです。
アプリケーションからGPUを操作して推論をするために、ソフトとハードとの間を橋渡ししてもらう仕組みが必要になります。
例えば、NVIDIAのGPU向けのAPIとしてCUDAというものがあります。AMDでそれに該当するROCmというAPIもあります。
しかしROCmはARMのCPU向けのビルドができません。なので今回は、代わりにVulkanというAPIを使います。

これはAndroidスマートフォンなどでも利用されているAPIで、ARMのCPUでも使うことができます。
Llama.cppはVulkanに対応しているのに対して、OllamaはVulkan非対応でした。理由は不明です。
非公式のVulkan対応フォークもあるのですが、うまくビルドできませんでした。これをRaspberry Pi 5で動かせた方がいらっしゃいましたら、是非コメントにてご教示願います。
今回は標準のLlama.cppをVulkanに対応した形式でビルドします。
$ cmake -B build -DGGML_VULKAN=ON
$ cmake --build build --config Release詳細はLlama.cppのリポジトリのドキュメントに記載がありますので、そちらをご確認ください。
Vulkan関連のライブラリもインストールします。
$ sudo apt-get install -y libvulkan1 mesa-vulkan-drivers vulkan-tools libvulkan-dev glslc推論の動作確認
機材準備
冷却のため、サーキュレーターに載せた状態で動作させます。

DeepSeek-R1 7B蒸留Q4KM量子化モデル
まず、DeepSeek-R1の7B蒸留Q4KM(4bit)量子化モデルを使って実験を行います。

pi@raspi5:~/llama.cpp $ ./build/bin/llama-cli -m ../models/DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf -ngl 40 -t 4 --repeat-penalty 1.1 --interactive起動時のオプション-ngl 40で、GPUにロードするニューラルネットのレイヤー数を指定しています。今回はDeepSeek-R1が持つレイヤー数より多い値を指定したので、全てのレイヤーがロードされるはずです。
起動すると、29層すべてのレイヤーがロードされていることがログから確認できました。
1. load_tensors: loading model tensors, this can take a while... (mmap = true)
2. load_tensors: offloading 28 repeating layers to GPU
3. load_tensors: offloading output layer to GPU
4. load_tensors: offloaded 29/29 layers to GPU
5. load_tensors: Vulkan0 model buffer size = 4168.09 MiB
6. load_tensors: CPU_Mapped model buffer size = 292.36 MiB無事に起動できたので推論速度を比較してみます。
簡単なプロンプトを打ち込んで文章を生成させてから、速度を計測しました。
その結果を、以前同モデルを使ってCPUで推論したときの速度と比較したところ、次のような結果になりました。
| CPU | RX6600XT | |
|---|---|---|
| 生成速度[tokens/s] | 2.3 | 12.0 |
実に5倍以上も生成速度が向上していることがわかります。
Mistral-Nemo 13Bモデル
以前の動画で、RasPiでDeepSeek-R1の14B蒸留モデルを使おうとしたところ、RAMが足りずに実行できなかった様子を紹介しました。今回のこのGPUではどうなるのでしょうか。
Mistral AI 社が開発したMistral-Nemo の、CyberAgent社による日本語ファインチューニング済み、13Bサイズ、Q4KM量子化モデルを実行してみます。

pi@raspi5:~/llama.cpp $ ./build/bin/llama-cli -m ../models/Mistral-Nemo-Japanese-Instruct-2408-Q4_K_M.gguf -ngl 41 -t 4 --repeat-penalty 1.1 --interactive41層すべてのレイヤーをGPU上に展開して起動することができました。
VRAM上にはOSが載っていない分、容量に余裕があるなどの理由が考えられます。また、モデルによってパラメータ数やレイヤー数などの都合で必要な容量の違いはあるかと思います。
別ウィンドウでGPUの状態を観察していると、起動した瞬間にVRAMの使用量が0%から94%に跳ね上がったのが確認できます。
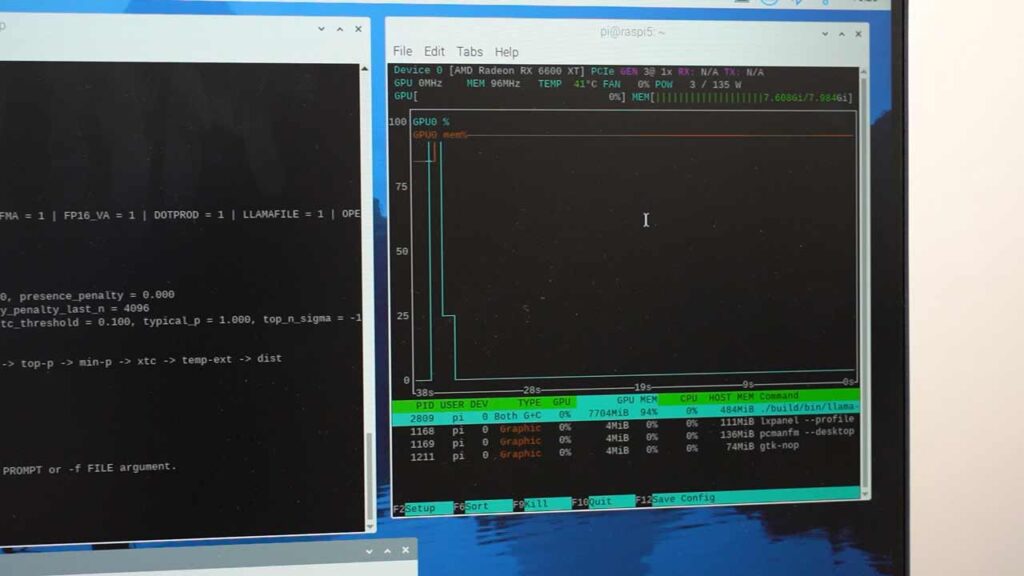
適当なプロンプトを打ち込んで生成速度を計測してみました。
このサイズのモデルでも、9~10[tokens/s]程度の速度が出ているようです。
TinySwallow-1.5B
最後に、逆に小さいモデルを動作させてみます。

Sakana AIが開発した日本語SLM(Small Language Model、小規模言語モデル)、TinySwallow-1.5BのQ5KM量子化済みモデルです。
pi@raspi5:~/llama.cpp $ ./build/bin/llama-cli -m ../models/TinySwallow-1.5B-Instruct.Q5_K_M.gguf -ngl 41 --repeat-penalty 1.1 --interactive16[tokens/s]程度の速度が出ました。これは体感的にはweb版のChatGPTなどと遜色ない速度です。
また、このモデルは小さいながらも高精度な日本語での受け応えができています。Raspberry Piのローカルでこれだけ回答の精度を保ったまま速度が出れば上々の結果ではないでしょうか。
Qwen2.5-Coder
Llama.cppのサーバ機能を使って、コーディング支援LLMであるQwen2.5-Coderを動かしてみます。

これはFIM(Fill-In-Middle)という方式のLLMで、文中の空いている箇所を推論することができます。これを利用して、コーディング時にカーソル位置に入るコードを推論し、候補を表示するオートコンプリート機能を持ったIDEの拡張機能などを使うことでコーディング作業が効率化できます。
VSCodeに、外部のLLMサーバと連携してコーディング支援を行う拡張機能であるContinueをインストールします。
そのクライアントとなるPCと同じLAN内で、サーバを立ち上げます。
$ ./build/bin/llama-server -m ../models/Qwen2.5-Coder-7B.Q4_K_M.gguf -c 4096 --mlock -ngl 49 --host 0.0.0.0 --port 8000Continueの設定jsonファイルに、のRaspberry Pi 5のIPアドレスとサーバ起動時に指定したポートを設定します。
"tabAutocompleteModel": {
"title": "Qwen2.5-Coder",
"provider": "llama.cpp",
"model": "qwen2.5-coder:14b",
"apiBase": "http://{Raspberry Pi 5のホスト}:8000"
},そしてVSCodeのエディタ上でコードを手で少し書いてみると、その先が予測されて表示されました。ここでTabキーを押すことで、その候補で確定させることができます。
推論が実行されている間はグラフィックボードのファンが回っている様子が観察できます。
私が普段コーディング時に使用しているGemini Code Assistantなどに比べるとレスポンスが遅いなど不便に感じることはありますが、月額費用がかかるGithub Copilotなどと違って、電気代のみのランニングコストで格安コーディング支援AIを実現ことができるというのは大きなメリットです。
前回の記事でも言及しましたが、Raspberry Pi 5+GPUの特徴は待機電力の低さなので、こういった用途には向いているかもしれません。
LLMと音声で会話する
黒い画面でのテキストチャットだけでは面白くないので、AIと音声で会話できるシステムを実装してみます。
せっかくなので、音声認識と音声合成もすべてローカルで行えるようにします。
なお、本記事で紹介したプログラムはGithubでも公開しております。ぜひ一緒にご確認ください。
ハードウェア構成
USBでDACとマイクを接続しました。これで音声の入出力をします。

Raspberry Pi 5からイヤホンジャックが廃止されているため、スピーカーはUSB接続する必要があります。
HDMI接続されたモニタから音声を出力することも可能であるとは思います。ただし、それには前回の記事のカーネルコンパイル時に必要なモジュールを設定する必要があります。これについては検証していません。
ソフトウェア構成
PythonスクリプトでLLMとの音声対話を実現するにあたって、llama.cppをPythonから扱えるようにしたライブラリ、llama-cpp-pythonを使用します。
また、音声認識にはOpenAIが開発したローカル音声認識モデルWhisperを利用します。
マイクから入力された音声でWhisperを使って文字起こしするという処理をPythonから操作したいので、それを実現してくれるwhisper-micというライブラリを使用します。
これらのライブラリはすべてpipからインストールできます。
なお、インストール時にはvenvなどで仮想環境を切り分けておくことを強く推奨します。venvの使い方についての説明はここでは割愛します。
また、llama-cpp-pythonはインストール時に環境に併せてビルドする必要があります。今回は、Vulkanを利用するので、そのための引数を渡してpipでインストールします。
(venv)$ export GGML_VULKAN=on
(venv)$ sudo apt install portaudio19-dev
(venv)$ CMAKE_ARGS="-DGGML_VULKAN=on" pip install --no-cache-dir llama-cpp-python
(venv)$ pip install whisper-mic
音声合成と発話ではOpenJTalkで生成したwav形式の音声ファイルをaplayを用いて再生しています。
今回は動作の軽さからOpenJTalkを選定しましたが、Raspberry Pi 5の性能であればVOICEVOXなど他の音声合成エンジンも動かすこともできるかと思います。
動作確認
実際に実行してみるとこのような感じです。
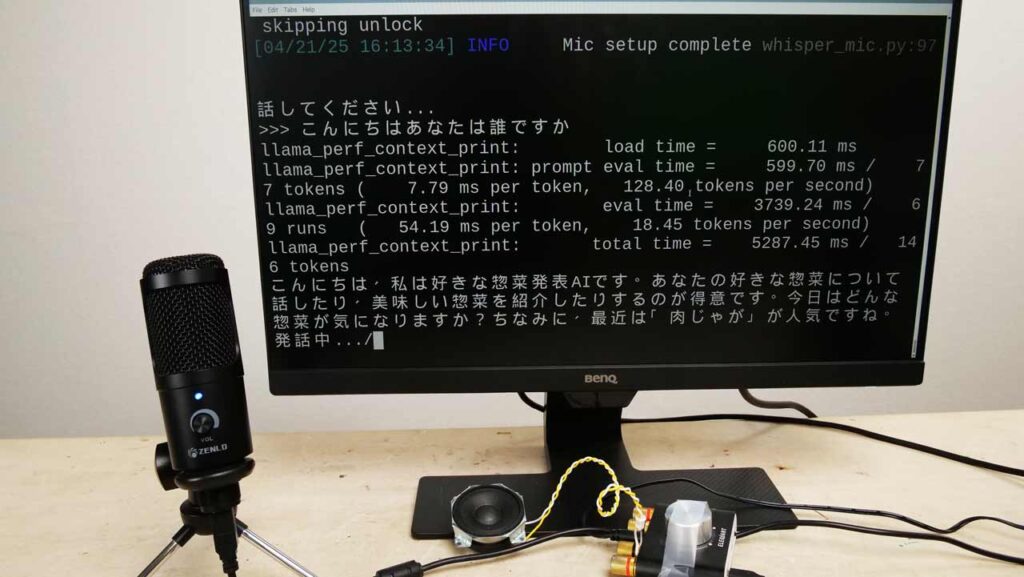
イマイチ動作が遅いですが、ユーザーの発言に対する回答が日本語の音声として発話され、音声会話が実現できています。
動作の遅さの原因は、Whisperが推論をする際にGPUではなくCPUを使用している点です。
また、プログラムの都合上生成した文章をリアルタイムに出力していくことができないという点も遅さの要因の一つです。文章がすべて完成してから発話の処理を開始するようになっています。
生成された文章が長くなればなるほど、推論開始から発話までの時間が長くなります。
そのため、生成された文章を改行やスペース、句点などで文章を区切って、短いスパンで音声合成と読み上げ処理を実行するようにしているのも工夫の一つです。
スマートホームアシスタントを作る
スタンドアロンで完結する音声会話システムができたところで、ローカルで動作するスマートホームアシスタントを作ってみます。
スマートホームアシスタントとは、Google Nest Hubのように音声によって家電などを操作できるデバイスのことです。
Nest Hubはネット接続されていることで、Googleのサーバによってホスティングされている音声認識APIと音声合成APIを呼び出すことによって小さいデバイスでの受け答えを実現しています。
これをRaspberry Pi 5 とGPUによって、外部との通信を一切せずに実現しようという試みです。
ハードウェア構成
本来であれば家電を操作するためのデバイスが必要になりますが、今回はRaspberry Pi 5のGPIO出力からLEDを光らせることにしました。

この家の模型には、各階にLEDが1つずつ接続されていて、それぞれが「1階」「2階」の照明を表しています。

照明には、イチケンが販売しているフレキシブルな配線付きLED、FlexiGlowを使用しています。
FlexiGlowについては以下のページをご確認ください。


このGPIO出力にLEDの代わりにリレー制御回路などを接続すれば、家電を制御することができるようになります。
ソフトウェア構成
今回もPythonを使ったスクリプトを作成しました。
このプログラムで重要な部分はシステムプロンプトです。システムプロンプトとはLLMとの対話実行前にあらかじめLLMに入力されるテキストです。
if SMART_HOME:
history.append({"role": "system", "content": "あなたはRaspberry Piの上で動作しているスマートホームアシスタントです。\
あなたはGPIO出力によって家の1階と2階の照明を制御することができます。ユーザから照明に関する要求があった場合は、ユーザの要求を達成するために制御を実行します。\
コマンドを生成することで、GPIOが制御されます。コマンドは以下の構文です。\
/GPIO \{出力番号\} \{状態\}\
「1階」が出力番号0、「2階」が出力番号1に対応しています。\
音声認識の都合上、文字が誤認される場合がありますが、コマンドを解釈するうえで読みが似ている場合、また、意味が近い語は同一と解釈してください。\
状態は0,1のみ入力可能です。0がオフ、1がオンです。\
操作をする場合は、コマンドのみを生成して他の文は生成しないでください。\
実行が完了したのち、システムから返ってくるメッセージの内容を判断して、成功/不成功を日本語の文章として報告してください。"})
else:
history.append({"role": "system", "content": settings.SYSTEM_PROMPT})システムプロンプトによって、家電操作の要求があった場合にある特定の構文に則ったコマンドを生成するように、システムプロンプトで指示しています。
/GPIO {階数} {状態}プログラムでは、LLM側の発言を監視し、生成された文章が”/GPIO”に前方一致する場合、その行内をコマンドとして解釈してGPIOを操作します。一度の発言内に複数行のコマンドがある場合にも対応できます。
response = tc.chat_with_llama(text,history)
#LLMの発言を行ごとに反復
for line in response.splitlines():
#行頭がコマンドとして解釈できるなら
if line.lower().startswith("/gpio"):
#コマンドパーサに行を渡して実行結果を得る
result=command_parser(line)
#実行結果をLLMの言葉で説明してもらう
response = tc.chat_with_llama(result,history,role="system")これはあくまで私が考えて実装した手法なので、実際のスマートホームアシスタントが使っているアルゴリズムとは異なる可能性があります。おそらく実際のスマートホームアシスタントはLLMから外部のAPIを操作するためのMCP(Model Context Protocol)という仕組みを使っているはずです。
フルスクラッチで実装できる範囲で、もっとスマートな方法をご存知の方はぜひコメントで教えてください。
動作確認
プログラムを実行し、マイクに向かって「1階の明かりをつけてください」などと言うと対応する照明が点灯します。
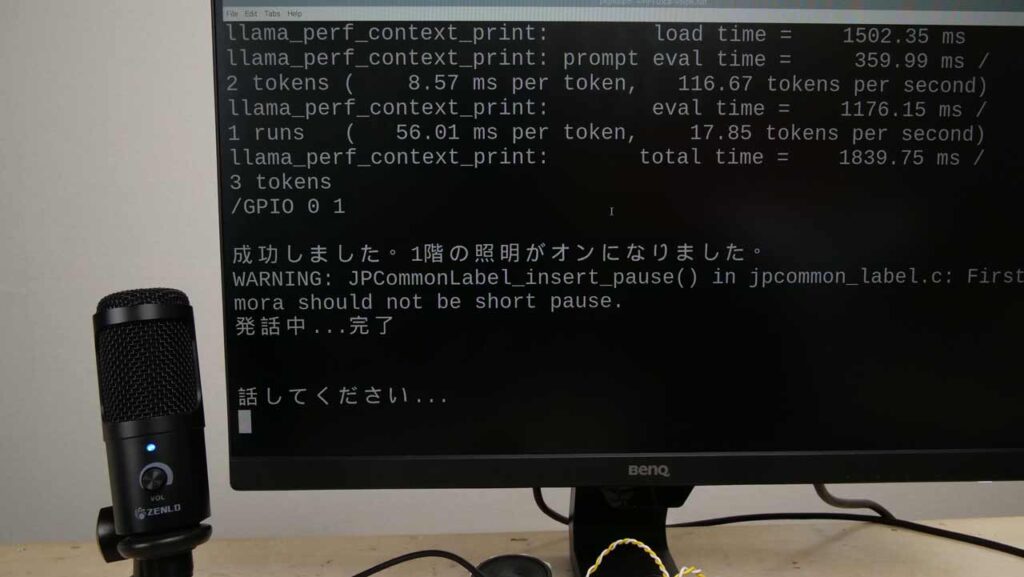

またそれだけでなく、「上の階の照明をつけてください」、「すべての階の照明を消してください」、「2階の照明を消さないでください」などといった曖昧だったり分かりづらい言い方をしても、きちんと正確に認識してくれます。
これは文中に含まれる単語のみを条件分岐で判定する方式ではかなり実現が難しいことです。
まとめ
今回の実験を経て、完全にスタンドアロンで音声会話するシステムを作ることができました。
これだけ大掛かりになってしまう機材にデスクトップPCに対する大きな優位性を見出すことは難しいかもしれませんが、本記事が貴方のクリエイティブな活動の一助になれば幸いです。
これを活かして独自のエッジAIシステム開発に繋げることができましたら、ぜひコメントで教えてください。
また、本記事の内容は、動画でも公開しておりますので、ぜひそちらもご覧ください。





コメント